The first step in building a data science model is: Collecting data.
For beginners in data science, it is easier to grab ready-to-use data files in CSV format from many available public data sources. If anyone is interested, I will list the sites for free publicly available in the future article.
This article is for anyone who would like to learn how to scrape website quickly and easily using the tool in Python you already know (Pandas). I will cover a little bit on the basics of web scraping before talking about the libraries.
What is “web scraping” and why we need it?

The term “Web Scraping” basically means:
Extracting data from the websites
In another word, it is the same as when: you browse one website, copy the part you want, then exit. The differences are:
- You can program to automate this task
- You can run this program in parallel to browse more than one page at the same time
This is nothing new in the web industry. The tech giants such as Google or Bing do it every single day in order to build the search engines we are using.
But if we are not building search engine, do we need web scraping?
If you are working with data, then YES. Sometimes we want the data from the sites that not providing API. The basic skill in web scraping will come in very handy.
It is also quite useful skill to have for automate personal stuffs such as:
- Collect the product prices from all popular e-commerce websites and find the best deal every day
- Detect the change in stock / bitcoin prices to find the best time to invest or sell in real-time
- etc.
Is Web Scraping legal?

Disclaimer: I am data scientist / web developer, not a lawyer. I would recommend to contact the lawyer if you are unsure about your situation.
I think it is a good idea to discuss about this topic upfront, before you spend a lot of effort in scraping.
Web Scraping is in the grey area. The websites you scrape from have to right to sue you anytime, especially if you are violating their terms and conditions.
You may think this does not make sense. Think about if you are openning a sourvenir shop, and your competitors come in to take photos of everything you are selling. So that they can copy and produce it themselves. They are basically using your own space to benefit themselves. You as the shop owner probably does not like that.
(I know this is not the best analogy, but hopefully it made a point)
Now I sounds like I am making you scared of web scraping. Don’t worry, I will recommend what you can do in the next section.
If you want to read more on this topic, I recommend you to read this article by Ben Bernard.
Advice for doing web scraping the polite way

Here is something you can check before scraping any website:
- Read the Terms of Services of the website you are about the scrape. If it says something similar to “The use of automated systems or software to extract data from this website is prohibited…“, then you are not allowed to scrape.
- Check robots.txt on each website if you are allowed to scrape. For example, here is Facebook Robots.txt file. If it has “Disallow: /”, you are not allowed to scrape the whole site. If it has other paths, you are not allowed to scrape those paths.
- Check if the website provides API for you to request the data. Every big websites usually have one to prevent web scraping.
- Contact the website owner directly to ask if you can scrape. They may be able to provide you with the data file in easy-to-use format. Write a short email can save you a lot of time!
- At this point, you can be ready for web scraping. Be mindful with the website you are scraping. Don’t request aggressively (e.g. 5 pages every second) or some websites might block you forever.
Now you are ready to do web scraping! Let me show you step by step. It is not difficult as you may think.
Why should we use Selenium Webdriver?

I heard about Selenium Webdriver when I went to visit a data science consultant company in Thailand. They were scraping data to train their deep learning model.
Last month I did a small side project which require scraping an old website. I remembered about Selenium and started learning it while working on the project.
There are multiple web scraping tools out there. Some of the tools are online (usually have price tags), while some are free libraries on programming languages such as Python or NodeJS.
Same as everything in the tech industry, there is no one perfect tool. Here are the pros and cons of Selenium Webdriver I found while using it:
Pros of using Selenium Webdriver
- Easy to learn and the scraping process is similar to other popular tool e.g. BeautifulSoup.
- Unlike other web scraping libraries such as BeautifulSoup, Selenium Webdriver open the real web browser window. It will see everything we see. This is very useful for modern websites with heavy JavaScript which cannot be captured without browser.
- Selenium Webdriver supports human-like interaction such as clicking the button.
Cons of using Selenium Webdriver
- It is slow. It will start scraping when the browser finished loading website. You will waste time and Internet bandwidth for unnecessary CSS and JS files.
- Paralellization is not as efficient as other libraries. Because it require opening the real web browser window for each page. This can eat up your RAM pretty quickly.
[Tutorial] Web Scraping with Python & Selenium Webdriver
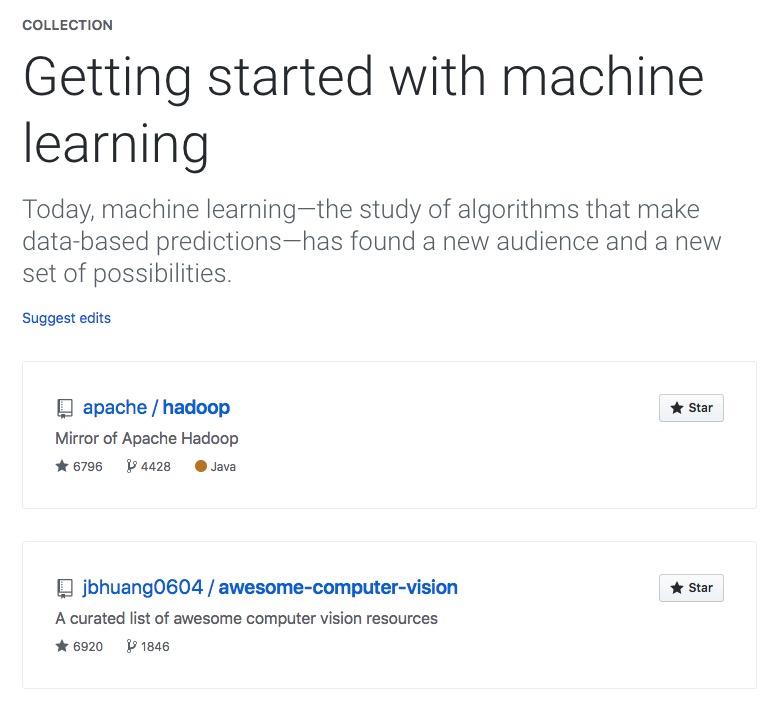
The goal of our web scraping project
We would like to build a collection of interesting open-source machine learning projects. Therefore, we will scrape top machine learning projects from this Github Collection.
(If this collection is closed in the future, you can find other collections from Github > Explore page).
Tech we need for this project
- Python (version 2.X or 3.X should be okay. I am using Python 3) – The easiest way to install Python on your machine is Anaconda.
- Selenium Webdriver for Google Chrome: Chromedriver – Download it and place it anywhere on your machine.
- Python Libraries – Install them with Python command line ‘pip install xxx’ or ‘!pip install xxx’ in Jupyter Notebook
- Selenium Webdriver – pip install selenium
- Pandas (For exporting data) – pip install pandas
Step 1) Import Selenium Webdriver & Test
After you have installed everything we need, you can import the selenium libraries
from selenium import webdriver # allow launching browser from selenium.webdriver.common.by import By # allow search with parameters from selenium.webdriver.support.ui import WebDriverWait # allow waiting for page to load from selenium.webdriver.support import expected_conditions as EC # determine whether the web page has loaded from selenium.common.exceptions import TimeoutException # handling timeout situation
Prepare the code for easily opening new browser window (This will be useful when we are doing parallelization)
driver_option = webdriver.ChromeOptions()
driver_option.add_argument(" — incognito")
chromedriver_path = '/Users/woratana/Downloads/chromedriver' # Change this to your own chromedriver path!
def create_webdriver():
return webdriver.Chrome(executable_path=chromedriver_path, chrome_options=driver_option)
Note that you have to change “chromedriver_path=’…’” to the path you are storing Chromedriver. If you don’t know the path, simply drag and drop the folder into Terminal window. It should show the path.
Step 2) Open the Github page & Extract the HTML elements we need
We can start scraping by passing the URL to the Webdriver:
# Open the website
browser = create_webdriver()
browser.get("https://github.com/collections/machine-learning")
There will be a Google Chrome window opens with the URL we specified. This means we open the browser successfully.
Next, we would like to extract the name and URL of all projects listed on this page. We can right click on the web page and click ‘Inspect‘ to view the underlying HTML of this page.
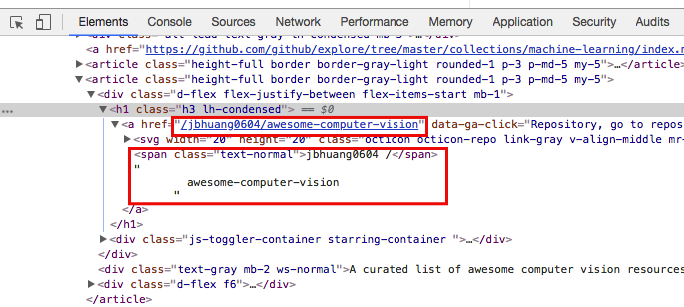
We found that each project has <h1> tag with class “h3 ln-condensed”. Therefore, we can extract all projects using the following code:
# Extract all projects
projects = browser.find_elements_by_xpath("//h1[@class='h3 lh-condensed']")
You can select any elements on the webpage using XPath. If you are not sure which XPath command to use, I found this XPath Cheatsheet to be very helpful.
The above code will store each <h1> elements and their children tags in the list. We can iterate through the list to extract each project’s name and URL using the following code:
# Extract information for each project
project_list = {}
for proj in projects:
proj_name = proj.text # Project name
proj_url = proj.find_elements_by_xpath("a")[0].get_attribute('href') # Project URL
project_list[proj_name] = proj_url
I introduced 2 useful commands to extract information:
- x.text – Extract the raw text from the element x
- x.get_attribute(‘y’) – Extract the value in attribute y from element x
Note that you can do advanced actions such as clicking on the link to scrape the deeper information. For this tutorial, we will stop here.
After we finished extracting, remember to close the browser using this command:
# Close connection browser.quit()
Step 3) Save the data to CSV using Pandas
Now that we have the data stored in Python dictionary, we will generate Pandas table from the dictionary and export CSV file.
We can convert the dictionary to Pandas DataFrame using this code:
# Extracting data project_df = pd.DataFrame.from_dict(project_list, orient = 'index')
Here is what our DataFrame looks like:
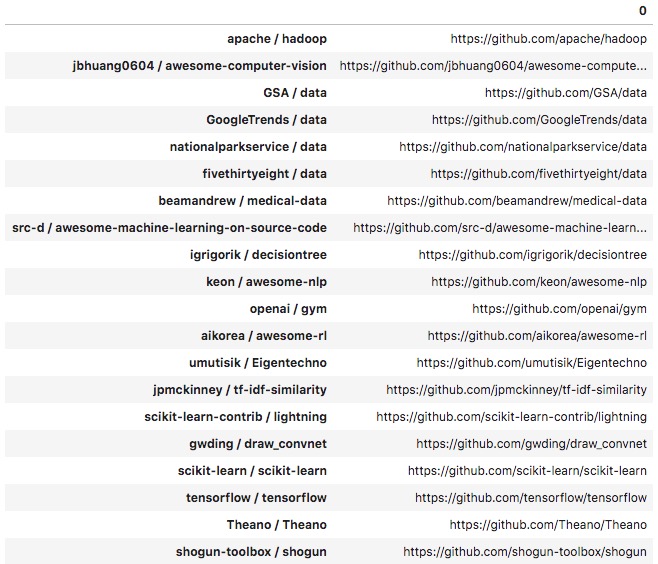
You can see that we have to fix this a little bit to have appropriate column names. We can do it using the following code:
# Manipulate the table project_df['project_name'] = project_df.index project_df.columns = ['project_url', 'project_name'] project_df = project_df.reset_index(drop=True)
This is the our final data frame:

For the last step, we can save this DataFrame as CSV file using the following code:
# Export project dataframe to CSV
project_df.to_csv('project_list.csv')
We can use this CSV file for further analysis, or share with our team for other purposes.
[Tip] Speed up web scraping with parallelization
As mentioned earlier that you can do web scrape faster by scraping many pages at the same time. You can use the ‘concurrent’ library in Python to accomplish this.
Here is the example code for doing parallelization in web scraping:
from concurrent.futures import ProcessPoolExecutor import concurrent.futures
def scrape_url(url):
new_browser = create_webdriver()
new_browser.get(url)
# Extract required data here
# ...
new_browser.quit()
return data
with ProcessPoolExecutor(max_workers=4) as executor:
future_results = {executor.submit(scrape_url, url) for url in urlarray}
results = []
for future in concurrent.futures.as_completed(future_results):
results.append(future.result())
urlarray = List of all URL you would like to scrape
You can change max_workers=4 to other number. Note that this code will open 4 browser windows at the same time.
As I mentioned earlier, please be mindful when scraping a website. They can block or sue you at anytime, especially when you open multiple connections to flood their websites.
For the future web scraping project
I am considering using the “Headless Chrome” which will makes this process faster, while I will still have control over
I hope this tutorial is useful for someone who would like to get start in web scraping. Feel free to ping me on Twitter @woraperth for any question 🙂
Leave a Reply