เพิ่งซื้อหนังสือ “สถิติ ฉบับการ์ตูน” ของ สสท. จาก Kinokuniya มา เพราะอยากไปศึกษาต่อพวก Data Science เลยต้องหาความรู้ที่เกี่ยวข้องมาใส่สมองก่อน เลยเอามาสรุปในนี้
บทที่ 1 : ค่าเฉลี่ย ความแปรปรวน และส่วนเบี่ยงเบนมาตรฐาน
ภาษาไทยมันดูงง ๆ ถ้าเป็นอังกฤษ คือ
- ค่าเฉลี่ย = Mean / Arithmetic Mean (แทนด้วยตัว มิว)
- ความแปรปรวน = Variance (แทนด้วย s^2 หรือ ซิกมา^2)
- ส่วนเบี่ยงเบนมาตรฐาน = SD (Standard Deviation) (แทนด้วย s, ซิกมา)
ตัวย่อดูจากในรูปได้เลย (สมการไม่เกี่ยวนะครับ อย่าไปสนใจ)
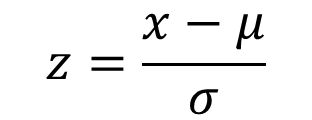
ตัว u คือ มิว = Mean ส่วนตัวกลม ๆ คล้าย ๆ เลขหก คือ ซิกม่า = SD นั่นเอง
หนังสือเล่มนี้อ่านแล้วคิดถึงตอนเรียนมหาลัย จะเรียนแล้วพูดกันว่า ตกมีนว่ะ, มีนพอดีว่ะ, ตกมีน 2 SD ฯลฯ อะไรแบบนี้ พออ่านบทที่ 1 จบก็เข้าใจเลยว่าเค้าหมายถึงอะไร
Histogram
คอนเซปต์แรก คือ เวลามีข้อมูลเยอะ ๆ เราจะเอามาวาดเป็นกราฟเพื่อดูว่าข้อมูลมันเป็นอย่างไรบ้าง กระจัดกระจายแค่ไหน อะไรแบบนี้ ซึ่งจะเรียกว่า Histogram
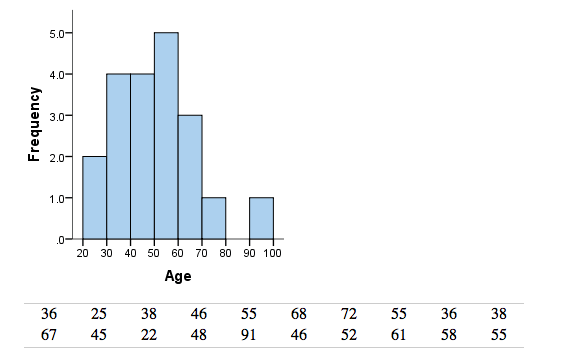
ใน Histogram เราจะเอามาข้อมูลมาแบ่งเป็นช่วง ๆ ก่อนพลอตกราฟ เช่น ข้อมูลอายุทั้งหมด เอามาแบ่งเป็นช่วงอายุละ 10 ปี เป็น 20-30, 30-40, …, 90-100 ก็จะแบ่งได้แบบนี้ (เพิ่งรู้ว่าภาษาอังกฤษเรียกแต่ละช่วงว่า bin)
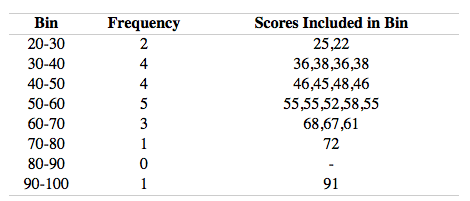
ซึ่งช่วง bin จะเป็นอะไรนั้น เค้าบอกว่าต้องแล้วแต่วิจารณญาณเลย ถ้าเลือก bin ถูกช่วงก็จะเห็นข้อมูลอะไรที่มันซ่อนอยู่ได้ง่ายขึ้นด้วย
สูตรในการเลือก bin แบบคร่าว ๆ คือ
- เอาจำนวนข้อมูลไปใส่ root เช่น มีข้อมูลคน 100 คน ก็เอาไปใส่ root = sqr(100) = แบ่ง 10 bin
- จากนั้นเอาจำนวนระยะของค่าทั้งหมดที่เราเก็บมา หารจำนวน bin ที่เราคำนวณมาตะกี้ เช่น เก็บข้อมูลคนอายุ 100-20 ปี / แบ่ง 10 bin = bin ละ 8 ปี
กราฟฐานนิยม 2 อัน (Binomal)
สิ่งที่ต้องระวังอย่างนึง คือ ค่าสถิติทั่วไปเหมาะกับ กราฟที่มีฐานนิยมอันเดียว (Unimodal)
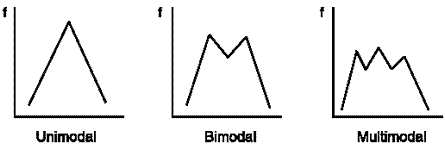
แต่ กราฟที่ฐานนิยม 2 อัน (Bimodal) มีโอกาสเกิดขึ้นได้ เพราะในบางครั้งเราไปเก็บข้อมูลเรื่องใดเรื่องหนึ่ง อาจจะมีคนที่ให้ข้อมูลสุดโต่งทั้งสองแบบ ไม่ชอบก็เกลียดไปเลย อะไรแบบนี้ หรือไม่อายุน้อย ก็อายุเยอะไปเลย
กราฟแบบ 2 ฐานนิยมมันทำให้ค่าที่คำนวณไม่ค่อยเป็นจริง เช่น แบบสอบถามเรามีคนทำอายุ 20 ปี 5 คน, 30 ปี 1 คน, และ 40 ปี 5 คน ค่าเฉลี่ยเราจะได้ออกมา 30 ปี แต่ไม่ได้แปลว่าคนทำแบบสอบถามเราอายุ 30 ปีเยอะที่สุด เพราะกราฟเป็นแบบ 2 ฐานนิยมนั่นเอง
เพราะฉะนั้นข้อมูลพวก คะแนนเฉลี่ย GAT PAT วิชานู้นนี้ ก็ไม่สามารถแปลความหมายได้ว่า คนส่วนใหญ่ได้คะแนน = คะแนนเฉลี่ย เพราะมันอาจจะเป็น Histogram แบบ 2 ฐานนิยมก็ได้
ค่าเฉลี่ย (Mean / Arithmetic Mean)
ค่าเฉลี่ยนี่ไม่มีอะไรมาก คือ การเอาค่าทั้งหมดมาบวกกัน / จำนวนข้อมูล
เช่น ข้อมูล 10, 20, 30 คิดค่าเฉลี่ยก็ 10 + 20 + 30 / 3 = ค่าเฉลี่ย 20
ความแปรปรวน (Variance)
สูตรของความแปรปรวน คือ ผลรวมของ (แต่ละค่า – ค่าเฉลี่ย)^2 / จำนวนข้อมูล
เช่น ข้อมูล 10, 20, 30 ค่าเฉลี่ย 20 คิดความแปรปรวนก็เอา (10-20)^2 + (20-20)^2 + (30-20)^2 / 3 = ความแปรปรวน 66.66
ที่มาของการคำนวณความแปรปรวน คือ เราต้องการหาว่าค่ากระจายกันมากแค่ไหน ก็ดูว่าแต่ละค่ามันห่างจากค่าเฉลี่ยมากน้อยแค่ไหน โดยเอา (แต่ละค่า – ค่าเฉลี่ย) จะได้ระยะห่างจากค่าเฉลี่ย แล้วเอามายกกำลัง 2 เพื่อให้ค่าเป็น + เสมอ (เพราะ 10 – 20 ได้ -10)
ยิ่งค่านี้น้อย แปลว่ากระจายกันน้อย ส่วนใหญ่ค่าใกล้ค่าเฉลี่ย แต่ถ้าเยอะ แปลว่าค่าส่วนใหญ่ห่างจากค่าเฉลี่ย
ส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation)
ค่า SD นี้จะคล้าย ๆ กับ Variance วิธีหา คือ เอา Variance มาเข้า square root นั่นเอง เช่น sqr(66.66) = SD เท่ากับ 8.16
SD เหมือนเป็นตัวที่ช่วยบอกได้ว่า ข้อมูลตัวใดตัวหนึ่งนั้นหลุดจากมาตรฐาน (ค่าเฉลี่ย) แค่ไหน
เช่น ถ้าคะแนนสอบทั้งห้องเฉลี่ย 50 คะแนน และมี SD = 8 คะแนน ถ้านาย A สอบวิชาเลขได้ 70 คะแนน แปลว่านาย A ได้คะแนนมากกว่าค่าเฉลี่ย (70 – 50) / 8 = 2.5 SD เราก็จะบอกว่า นาย A ได้คะแนนมากกว่า Mean ถึง 2.5 SD นั่นเอง
ข้อดีอีกอย่างของการใช้ SD คือ นาย A อาจจะได้คะแนนวิชาภาษาไทย 70 คะแนนเท่าวิชาเลขกัน แต่ถ้าวิชาภาษาไทยคะแนนเฉลี่ย 60 คะแนน และมี SD = 20 คะแนน แปลว่า นาย A ได้คะแนนภาษาไทยมากกว่า Mean แค่ 0.5 SD เท่านั้นเอง
สรุปว่านาย A เก่งเลข แต่ภาษาไทยนี่ก็ไม่ได้ต่างจากคนอื่นมาก
เดี๋ยวมาต่อบท 2
Leave a Reply